Twitter used to be a pretty safe place for your data, in a sense that you didn’t feel like it could be gone from one day to the next. But thanks to Elon willy-nilly poking at the system, firing half the staff, and being generally disruptive, you can’t be sure that your years of tweets are truly safe.
So the first thing you want to do is to request your data from Twitter while that still works. You can do this by going to “Settings and Privacy” in your Twitter account and then selecting “Download an archive of your data“, see images below.
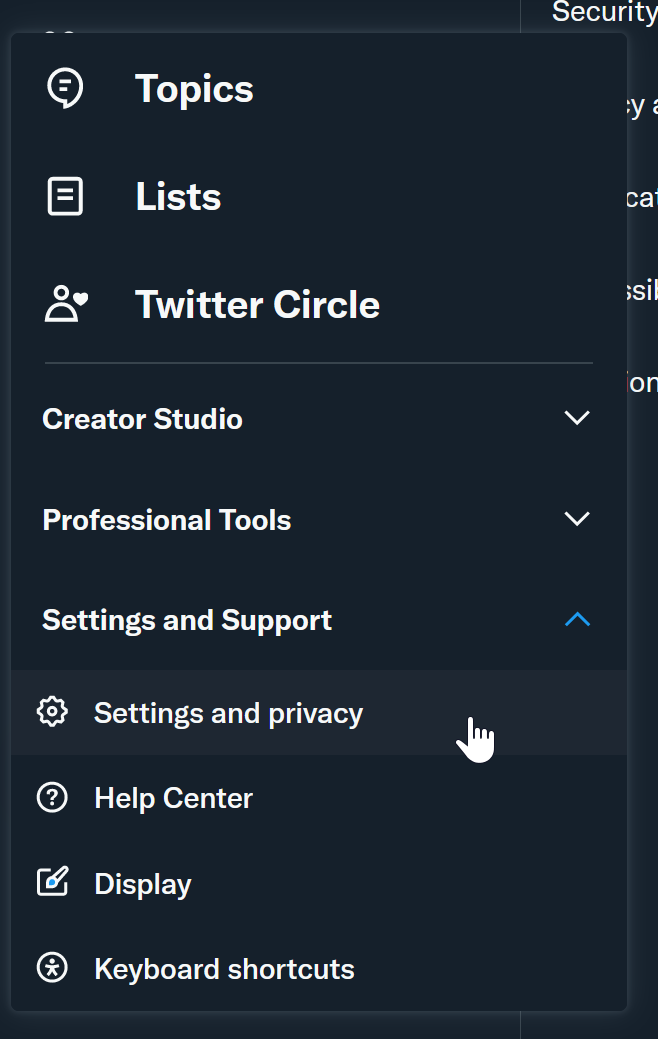

Alternatively, just click this link that should also get you there. Next step is to wait a couple of days for your archive to be ready for download. Depending on how many images and videos your posted, this file might be huge but totally worth it, if you want to hang on to your life’s tweet,
Am I missing something?
While there is an awful amount of data supplementing your tweets (such as all of your ad-impressions!), a few things see, a lot of the data is referring back to Twitter. Meaning, that should twitter.com be gone, all you’re left with are meaningless numbers; as Hector Martin pointed out a couple of days ago:
You won’t have the name, Twitter handle, or any other information of the people you follow and being followed by. Crucial information should you try to reconnect on other social networks such as Mastodon, cohost.org, or even Facebook LinkedIn.
Damn. What can I do?
Glad you asked! Because Hector’s post above made me dust off node.js again and write a tool for exactly that purpose. I call it TwitScraper
TwitScraper
TwitScraper is a command line program that reads the followers/following data from inside a twitter archive and fetches the missing metadata from twitter and saves everything in multiple formats.
- .json – like from the twitter archive but with additional fields
- .csv – easy to open in Libre Office, Open Office, Google Sheets, Excel…
- .png – screenshots of the profiles
I wrote the tool with node.js which means it should be platform independent. I tried my best to make a single package out of it but, alas, the waters of node.js are deep and treacherous and I had to give up after roadblocks to that idea kept popping up like whack-a-moles.
How to use
- Request your data from Twitter
- Download the zip
- Download and install node.js (a detailed step-by-step guide below)
- Download and unzip TwitScraper
- Move the twitter archive .zip into the same folder as TwitScraper
- Run TwitScraper
- Wait
TwitScraper opens an invisible browser that visits every profile among your following/followers, scrapes the data and then moves on to the next (because of this you need a stable internet connection). It takes about 1.5 seconds per entry so if you have a large number of followers or accounts you follow, this might take a while.
Detailed Installation Instructions
As mentioned above, I try my best to lead you through the process as an end-user, but you have to jump a few hoops first, sadly, such as install node.js. “Node.js is an open-source, cross-platform JavaScript runtime environment and library for running web applications outside the client’s browser” (source).
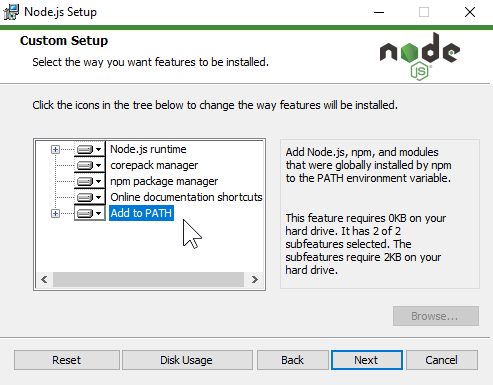
- Download the node.js installer for your platform and install it.
- Be sure to confirm that “Add to PATH” is also performed by the installer. If there’s a little red X on the icon, then change it to look like in the screenshot:
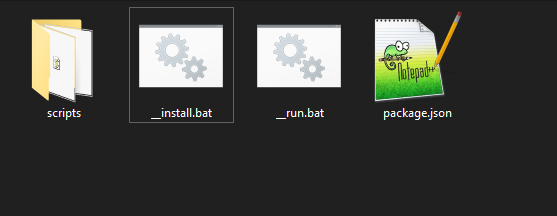
- Now download TwitScraper and extract the folder where you want the scraped data to end up in.
- The contents of the folder should look similar to this:
- Now you need to install the tool’s dependencies.
- If you’re on Windows, double click the __install.bat file. This should open a terminal window and install the necessary packages from the web. When the installation is complete, the window will close automatically.
- Alternatively, you can open a command prompt, navigate to the folder with the TwitScraper files and then enter
npm install - If you’re on MacOS: Open a terminal and navigate to the folder with the TwitScraper files (you can just drag-and-drop the folder into the terminal window). Then enter
npm install - If you’re on Linux, Open a terminal and navigate to the folder with the TwitScraper files. Then enter
npm install
- This should download the necessary files from the web and looks something like this:
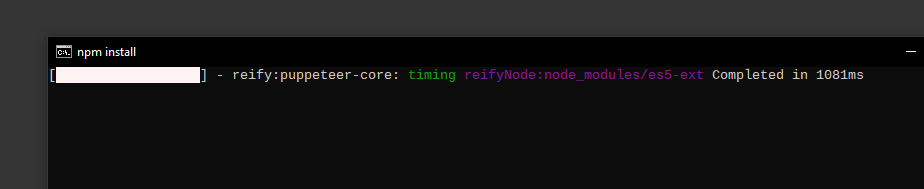
- On Windows, the console window automatically closes upon completion, on MacOS and Linux you should have a command prompt ready.
- Now put your Twitter archive .zip-file also into the TwitScraper folder. If doesn’t matter what its filename is, it’s just important that it’s the only zip file in that folder.
Congratulations! Now you can run TwitScraper:
- Windows: Run __run.bat to run TwitScraper with the default settings (see below).
- Alternatively (when you are in the command prompt window), type
node scripts/ts - MacOS: In the terminal window, type
node scripts/ts - Linux: In the terminal window, type
node scripts/ts
The terminal window will show you in real-time what’s happening and notifies you of any problems if might have.
Download
You can get TwitScraper from here. Yes, it’s really mere 10 kilobytes!
Additional options
Because TwitScraper is a command line program, you can pass it additional parameters but if you run it without any, it will use sensible defaults.
Parameters include:
-? | Displays the help dialog |
-sc n | Defines the dimensions of the screenshot. E.g. -sc 1 causes the app to take screenshots at 800×640px resolution, -sc 2 will double the size to 1600×1280 and so on. Default is 2 |
-sc 0 | Disable screenshot taking. Increases performance slightly |
-s n | Defines which item to start with. Useful, if you want to pick up, e.g. -s 124 to start with entry 124. Default is 1 |
-n n | Defines the number of entries to scrape, e.g. -n 100 to scrape 100 entries. Default is all the entries |
The screenshots will be stored in a newly created sub-folder, sensibly titles “screenshots” and in a respective sub directory for “followers” and “following”.
Examples:
node scripts/ts -sc 0 -s 20 -n 100Disables taking screenshot and starts from the 20th entry in the arrays and reads 100 entries (so from entry 20 to 120) instead of the defaults
node scripts/ts -sc 4Take screenshots at 4 times the default resolution
If you want to change more things, have a look at the source code in the scripts directory.
I hope this makes it relatively frictionless for you to retain ownership of your social graph!